Analysis of Algorithms
One of the first lectures you will have as a computer scientist is "Algorthims and Data Structures" where one of the introductory topics is the analysis of algorithms. This is a crucial subject because it allows us to compare different algorithms and design new ones by identifying areas for improvement. To determine which algorithm is better and which areas to optimize, we need a systematic way to analyze them.
This can be done by running the algorithm on inputs of various sizes and benchmarking them. However, such benchmarking is highly dependent on the hardware and software environments where the algorithm runs. Thus, a more abstract approach is needed, where we analyze algorithms in terms of time and space complexity which focuses on how an algorithm behaves as the input size grows.
In time complexity analysis, we measure the number of basic operations an algorithm performs relative to the size of the input, often focusing on the worst-case scenario. While some operations like addition may be considered "cheap" or fast, we focus on more expensive operations like multiplications, comparisons, and data movements (e.g., swaps). For example on the Intel Sandy Bridge(2011-2013) an addition is 3 cycles, and a multiplication is 5. However, this can change with different hardware and depends if SIMD instructions are used which can do multiple operations in parallel.
Similarly, space complexity measures the amount of memory an algorithm uses as the input size increases. For instance, an algorithm might use a constant amount of memory, or it might require additional memory proportional to the size of the input, such as a complete copy of the input data.
Asymptotic Analysis
We are primarily interested in how the time and space complexity of an algorithm grows as the input size increases, particularly in the worst case. To do this, we express the performance of the algorithm as a mathematical function and analyze its growth rate. The goal is to compare this growth rate with a set of standard growth functions, which are used as benchmarks. This is known as asymptotic analysis.
The most common growth functions, listed in increasing order of growth rate, are:
- Constant:
- Logarithmic:
- Linear:
- Log-linear:
- Quadratic:
- Cubic:
- Polynomial:
- Exponential:
- Factorial:
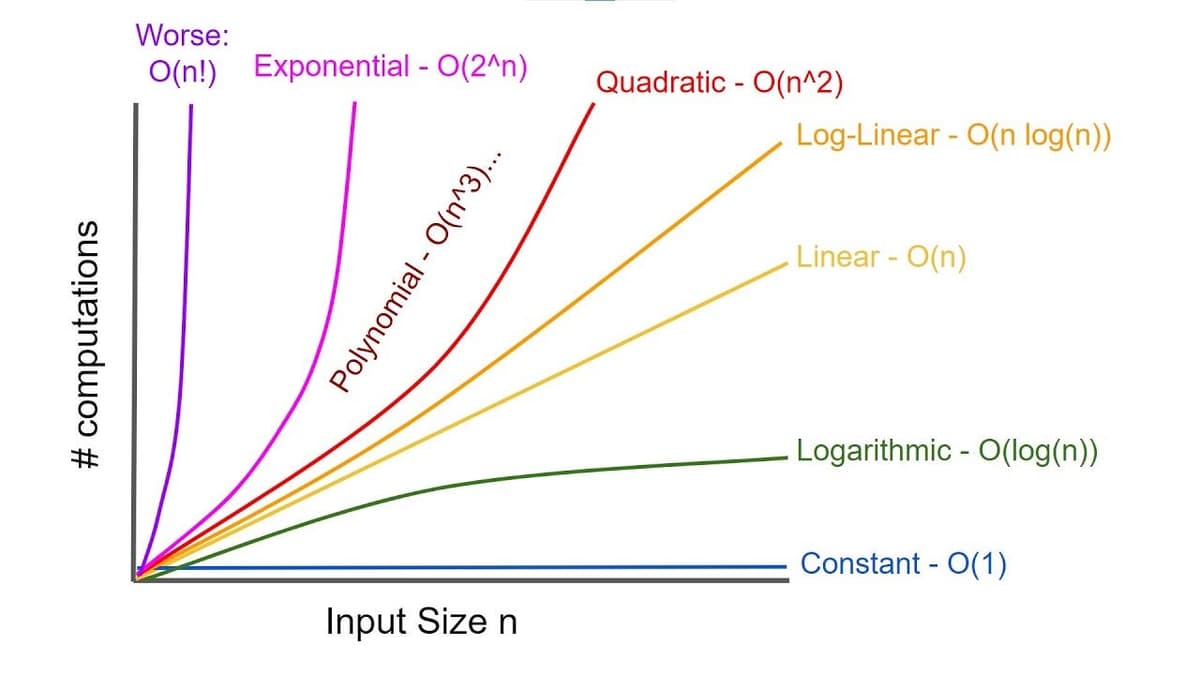
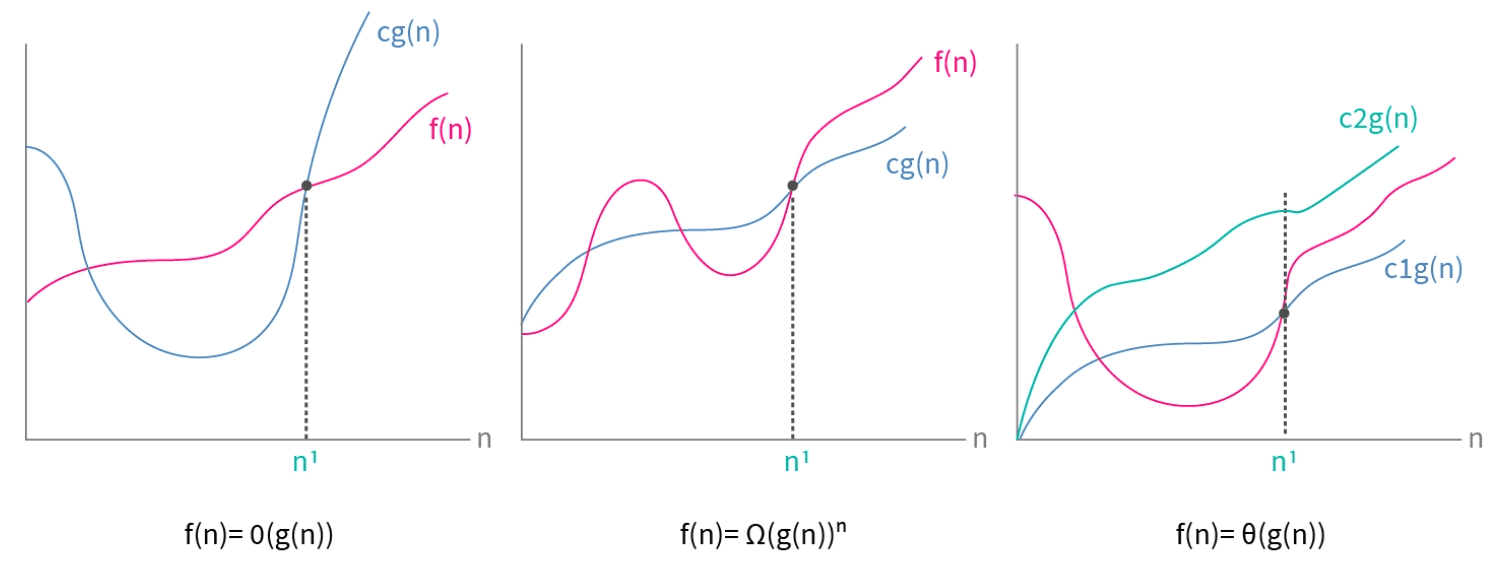
We can compare an algorithm's growth rate by determining which of these standard functions provides an upper bound. Specifically, if we have a function that represents the algorithm's work, we determine the smallest standard function such that grows no faster than a constant multiple of as becomes large. This is expressed as often said as " is big O of " or " is order of " and called Big O notation.
Big O Notation
The formal definition of Big O notation is as follows:
A function is said to be in , if there exist constants and such that:
In simple terms, at some point the function will always be less than or equal to for all .
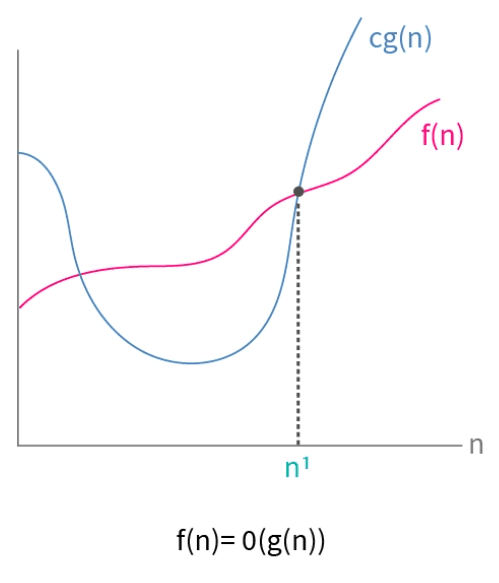
This method works because if we can find some and that satisfy the inequality, then we can also find different and that also satisfy the inequality as grows to infinity. This is because the function grows faster than so we can always find a and that satisfy the inequality, making the function an upper bound on the growth rate of . For this reason most students remember the following definition of Big O notation:
Suppress the lower order terms and constants to get the time complexity of the algorithm.
We want to show that is in . For this we need to find constants and such that for all . We can see that as grows the term will dominate the other terms so we can choose and to satisfy the inequality:
Therefore, is in . But we could also choose and to satisfy the inequality:
This is why we suppress the lower order terms and constants to get the time complexity of the algorithm. Let's also show that is in . We can choose and to satisfy the inequality or and .
Why is exponential just not any other base like ?
The reason is that the base of the exponential function does not matter when we are talking about the order of growth. Different bases can be converted to each other by a constant factor, so they are considered equivalent. For example, and because is a constant it can be absorbed into the constant factor and we can just say that is .
But why is then not ? Because the base of the polynomial function does matter. The difference between and is not just a constant factor, but a factor of because .
Telescoping
To be able to find the time complexity of an algorithm we need to be able to express the time complexity as a function of the input size . Most of the time the algorithm can be expressed as a reccurance relation, i.e. a function that calls itself with a smaller input size. These reccurance relations are actually just some series, i.e a sum of terms. For example the reccurance relation with is just the sum of the first even numbers.
Telescoping is then a method to solve these series/reccurance relations to find a closed form solution, i.e. a function that gives the sum of the series. This closed form solution can then be used to find the time complexity of the algorithm. The idea of telescoping is to write out the series for a few terms and then find a pattern to simplify or cancel out terms. Once we have our closed form we can check it is correct using proof by induction.
Lets show that the reccurance relation with is a sum of terms and can be solved using telescoping. The first step is to write out the first few expansions of the reccurance relation, it can also be helpful to write out the expansion step before the term:
Now we can see there is a pattern, with the trickiest part being connecting the subractions to and , but we can see that for its for its and for its .
However, we don't want the k in our closed form. To remove it we need to know when the recursive call will reach the base case. This is when so and . We can then substitute into the formula above to get:
Now that we have our closed form solution we can check that it is correct using proof by induction.
Proof by induction that is the correct closed form solution to the reccurance relation with .
- Base case: which is true.
- Inductive hypothesis: Assume is true for some .
- Inductive step: Show that if the hypothesis is true for then it is also true for .
Therefore, by induction is the correct closed form solution to the reccurance relation with .
Since we now have the correct closed form solution we can supress the lower order terms and constants to get the time complexity of the algorithm. In this case the time complexity is .
It is useful to remember some of the closed forms of common series like the sum of the first natural numbers to make telescoping easier.
But because we are subtracting the sum of the first natural numbers we can subtract the last from the closed form to get the sum of the first natural numbers:
The same can be done for other variations of the sum of the first natural numbers
Standard Multiplication
A classic introductory example of time complexity analysis is the multiplication of two numbers. Everyone learns how to multiply two numbers in primary school. You start by multiplying each digit of the first number by each digit of the second number and then adding them together whilst making sure to shift the numbers to the left depending on the position of the digit. For simplicity, let's assume that the numbers are of the same length as we can always pad the shorter number with zeros. For negative numbers we just need to check if only one of the numbers is negative and then add a negative sign to the result.
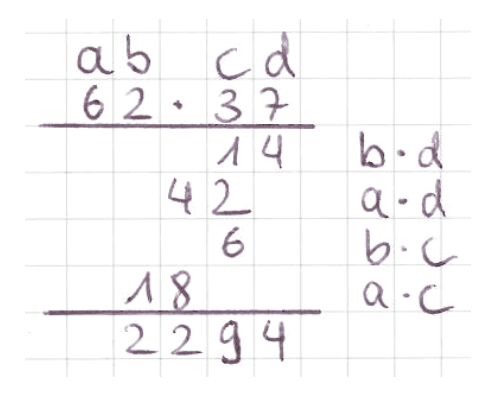
If we only focus on counting the number of multiplications we can see that for two -digit we get the following pattern and closed form solution:
The pattern is quite obvious. In fact, you can also derive the recursive relation with . Using telescoping, you can find the closed-form solution .
This recursive relation makes sense if you think about multiplying two numbers recursively. For example, in multiplying , you have multiplications for , and then you add another multiplications to handle the interaction between the leading digits (e.g., 4 with 23) and finally multiplications to multiply the leading digit (1) with the entire second number.
From the closed-form solution, we can quickly see that the time complexity of standard multiplication is . We can set and to satisfy the inequality for all .
Karatsuba Algorithm
The Karatsuba algorithm, named after Anatolii Karatsuba, was discovered in 1960 and revolutionized the multiplication of large numbers. Before Karatsuba's work, it was generally believed that was the best possible time complexity for multiplying two numbers. However, with Karatsuba's algorithm demonstrated it is possible to perform multiplication faster than the standard approach by reducing the number of multiplicative operations at the expense of a few more additions which are considered by far cheaper on most hardware.
The Karatsuba algorithm uses a divide and conquer approach, splitting each number into two smaller parts, multiplying them recursively, and combining the results in a clever way to remove a multiplication operation. The algorithm is as follows for multiplying two -digit numbers and where we assume is a power of 2 for easier splitting:
Where and are the first and second half of and and are the first and second half of . The algorithm then recursively calculates the following three multiplications recursively:
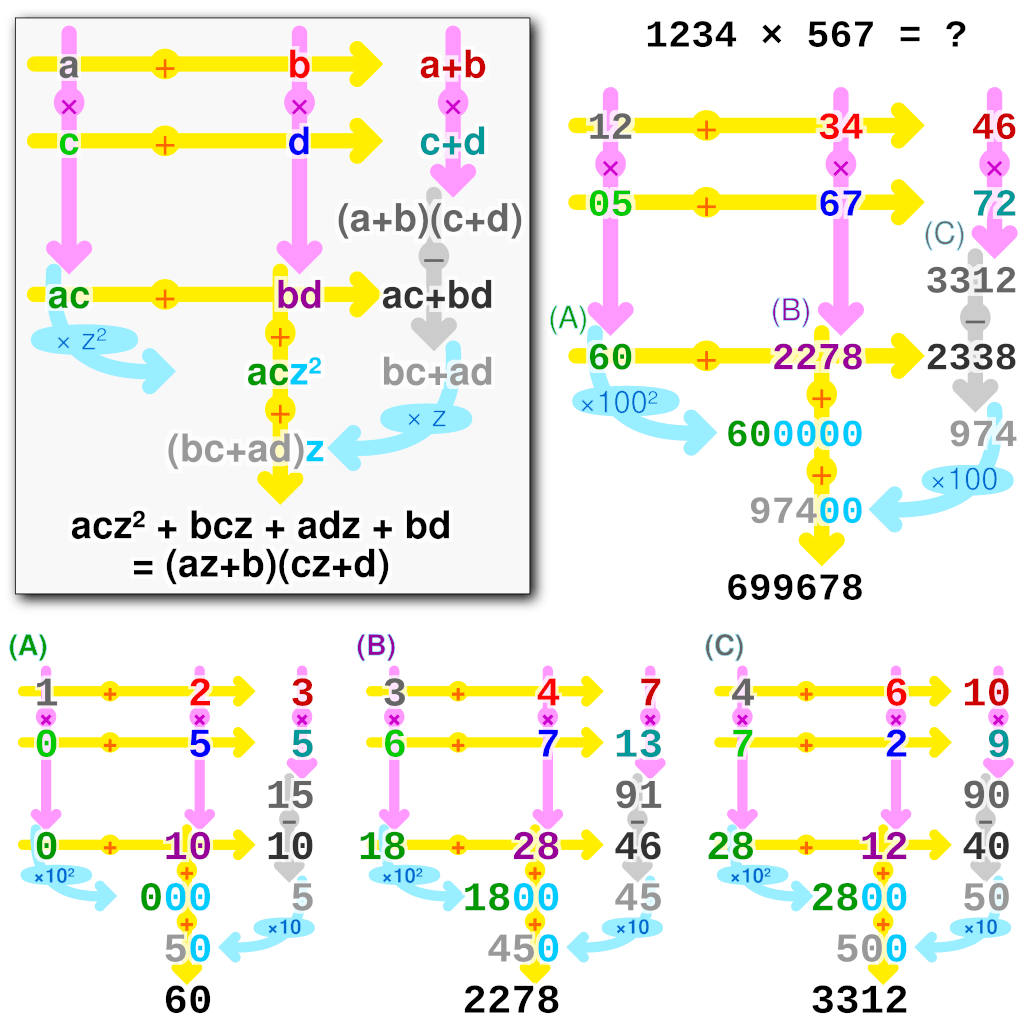
We can quiet easily see that the reccurance relation for the Karatsuba algorithm is as follows if we only focus on the number of multiplications:
This is because for the base case where so we only need 1 multiplication and then if we want to multiply two numbers with two digits we need to perform 3 multiplications and then for two numbers with 4 digits we need to perform 3 times a multiplication of two numbers with 2 digits etc. Using telescoping we can find the closed form solution and then show the time complexity of the Karatsuba algorithm.
We can see the pattern is as follows:
Proof by induction that is the correct closed form solution to the reccurance relation with .
- Base case: which is true.
- Inductive hypothesis: Assume is true for some .
- Inductive step: Show that if the hypothesis is true for then it is also true for .
Therefore, by induction is the correct closed form solution to the reccurance relation with .
However, we want the time complexity in terms of not so we need to find the relationship between and . We know that so . We can then substitute and use the fact that any number can be written as and the Logarithmic identity to get the time complexity in terms of :
Therefore, the time complexity of the Karatsuba algorithm is which is faster than the standard multiplication algorithm with time complexity .
Let's first show how it works for multiplying two 2-digit numbers so where and , , and .
If we now use the Karatsuba algorithm to multiply two 4-digit numbers it get's a bit more complicated by hand but the algorithm is the same. We split the numbers into two parts and then recursively multiply them:
Big Omega and Big Theta
Unlike Big O which is an upper bound on the growth rate of a function, Big Omega is a lower bound on the growth rate of a function. In simpler terms, Big Omega is used to describe the best-case scenario of an algorithm. More formally, a function is said to be in where is a growth function and the following condition is satisfied for all :
Big Theta combines the concepts of Big O and Big Omega. It is used to describe the tight bound on the growth rate of a function meaning it gives both an upper and lower bound on the growth rate of a function. More formally, a function is said to be in where is a growth function and the following condition is satisfied for all :
Master Theorem
The master theorem is a formula for quickly determining the time complexity of divide-and-conquer algorithms. More specifically, it determines the tight asymptotic bound theta for the time complexity of an algorithm that can be expressed as a reccurance relation. It requires the reccurance relation to be in a specific form, but if it is then the time complexity can be determined by just simply looking at the reccurance relation and extracting parameters from it. The reccurance relation needs to be in the form:
We can then determine the time complexity of the algorithm by looking at the parameters , and the function . We also need to calculate the following value which is the relationship between the number of subproblems and the size of the subproblems:
c_{\text{crit}} = \log_b a = \frac{\log_2 a}{\log_2 b} = \frac{\text{log of # subproblems}}{\text{log of relative size of subproblems}}The master theorem then determines the time complexity based on the following three cases:
Doesnt work for all cases, like fibonacci. Solve using telescoping.
Average Case Analysis
Using probability to find the average case time complexity of an algorithm. Seems annoying. Shows that the average case time complexity of quicksort is .